A text-to-speech tool using AWS Polly
Last year I wrote about converting books to speech, where I investigated using open source and free tools to scan textbooks and convert them into audio files.
At that time, the weakest part of the process was the actual text-to-speech part. Festival, the open source solution, doesn’t have great voices, hasn’t been updated in years, and is hard to use. I ended up using the Cepstral software, which works fine, but it has a graphical interface and is mainly for Windows and OSX. What if I want to automate the process completely from the Linux command line interface (CLI)?
Enter Polly
Last month, Amazon debuted Polly, the latest in its long line of web services. Using the AWS API, you can convert a snippet of text into speech in seconds. Like most AWS products, it is on-demand and low-cost — you get 5 million characters per month free for the first 12 months, and a million characters for $4.00 after that.
Submitting text to Polly is pretty easy, using the AWS CLI tool:
$ aws polly synthesize-speech --output-format mp3 --text "Here is my text" --voice-id Joanna output.mp3
The tricky part is that the API only allows ~1,500 characters of text per request. How do you convert a large amount of text, such as a book? Not finding a tool that would do this for me, I decided to create one.
aws-tts
aws-tts is a CLI tool that converts a text file into an audio file using AWS Polly. It’s designed to be simple to use and completely hands-off. All you need to do is specify the input file, and where you want the resulting audio file to be saved:
$ aws-tts my-test-file.txt resulting-speech.mp3
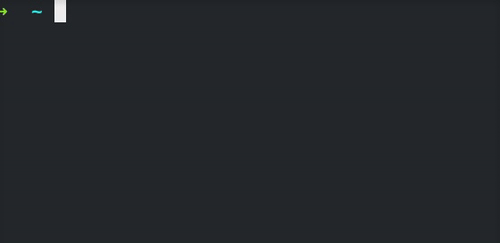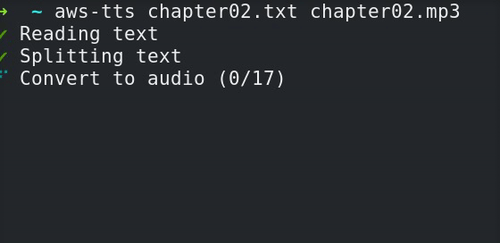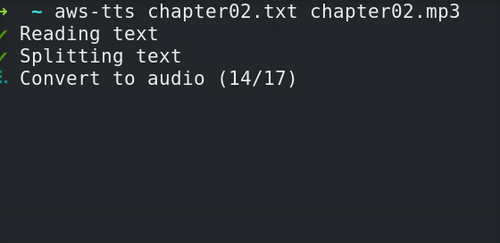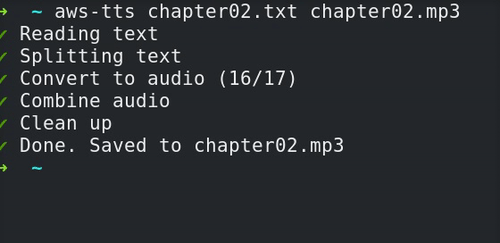
That’s it! If you want something other than an MP3 or the default voice (Joanna), you can specify those options on the command line.
Technical Details
All in all, the tool is only about 200 lines of code. The process is straightforward, but uses a few interesting libraries.
First, it splits the text into pieces. I used the textchunk module (which is basically sbd) to split the text into pieces small enough for AWS, without splitting the text in the middle of a word or a sentence.
Because even a moderate amount of text can be split into hundreds of pieces (textbook chapters for me divided into ~180 parts), we don’t want to exceed Amazon’s rate limits. To throttle the requests, I used the popular async module, specifically eachOfLimit(). The requests use the official AWS SDK library for Javascript. The resulting audio files are stored in a temporary file using tempfile.
Once all of the audio files are received, they are stitched together into one file using ffmpeg’s “concat” demuxer. I tried using the Emscripten port of ffmpeg so that users wouldn’t need ffmpeg installed on their machines, but I couldn’t get it to find the temporary files — it kept giving “file not found” errors, even when the normal ffmpeg binary worked fine. (If you have an idea of how to fix this, let me know.)
The asynchronous stuff (the API requests and the ffmpeg process) are handled with Javascript promises. The fs-extra module was used to provide extra filesystem functionality seamlessly over the top of Node’s built-in filesystem commands.
Finally, I used the nice ora spinner to provide feedback to the user while the process is running.
Results
AWS is a great platform and the Polly service provides a great way to convert text to speech.
- The speech quality is as good as anything else out there, and will only get better.
- It is much faster than the Cepstral software; a book chapter will encode in about a minute, whereas Cepstral takes almost an hour.
- It provides a cross-platform, command-line way to convert text to speech.
- It encodes to MP3 out of the box — no need to convert WAV/PCM files yourself.
The main advantage of Cepstral is that it has a relatively small, one-time cost. If you plan on converting a lot of text over time, especially for personal use, then the added inconvenience may not outweigh the costs you would accrue with AWS.
Get my TTS tool here: github.com/eheikes/aws-tts. It’s brand new, so please submit bugs & features to the GitHub repository.
|
Cacio |
estou tendo problemas com o ffmpeg
ele retorna:
Failed to read frame size: Could not seek to 1026
o comando que eu usei foi o:
ffmpeg -i Voz.mp3 voz.ogg
toysuae |
Hello, It seems helpful for me. Seriously I was just searching for the same problem.
Eric J |
Hello Eric! First off, thank you for developing this awesome program!
I’m a bit green to programming and anything invloving CLI sends a chill down my spine. I’ve gotten pretty far in the installation process but reached an inevitable roadblock.
I’m running all of this on my Dell, using windows 10. I got node.js v12.16.3 LTS installed, as well as ffmpeg 4.2.2 windows build (static linking?).
After running:
C:\Users\ericj>npm install tts-cli -g
I immediately saw warnings and errors. Eventually I reached a point where it terminated the install with the message:
npm ERR! Failed at the grpc@1.24.2 install script.
npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
npm ERR! A complete log of this run can be found in:
npm ERR! C:\Users\ericj\AppData\Roaming\npm-cache\_logs\2020-05-14T23_29_33_300Z-debug.log
Before running npm, I hadn’t noticed any prior errors. Furthermore, I can run any tts command and receive the following output:
C:\Users\ericj>tts
internal/modules/cjs/loader.js:960
throw err;
^
Error: Cannot find module ‘C:\Users\ericj\AppData\Roaming\npm\node_modules\tts-cli\tts.js’
[90m at Function.Module._resolveFilename (internal/modules/cjs/loader.js:957:15)[39m
[90m at Function.Module._load (internal/modules/cjs/loader.js:840:27)[39m
[90m at Function.executeUserEntryPoint [as runMain] (internal/modules/run_main.js:74:12)[39m
[90m at internal/main/run_main_module.js:18:47[39m {
code: [32m’MODULE_NOT_FOUND'[39m,
requireStack: []
}
I’m super lost in this realm, do you have any idea how I should move forward?
Thanks again,
Eric J
Eric |
Hi Eric!
It looks like the grpc module didn’t install successfully. What’s odd is if I run the install on my Windows 10 machine using Node 12.16.3, I don’t get that error.
The “Cannot find module” is also strange. Are you running the commands inside the “Node.js command prompt” that gets installed with Node.js (look under the Start menu)? It sounds like the Node/npm scripts might not be accessible.
Other ideas:
* Try installing grpc manually: `npm install grpc -g`
* Remove the module: `npm remove tts-cli -g` and try again.
* Uninstall Node.js and try installing again. I installed all the features (including “Add to PATH”) but did not install the Tools for Native Modules.
Side note: I am planning on making a graphical app of this when I have some time: https://github.com/eheikes/tts/issues/36
Serge |
Hi Eric,
Thank you for a wonderful tool. By the way, Google has just launched its own version of AWS Polly called Google Cloud Text-to-Speech API. From my point of view, voices with WaveNet are better than Polly. However, as far as I know, there is no command-line tool for converting books to speech by using Google Cloud Platform.
I’m wondering if you’re planing to develop something similar to your aws-tts tool for Google Cloud Text-to-Speech Platform.
Kind regards,
Serge
Eric |
Hi Serge,
I haven’t given any thought to Google Cloud’s TTS. I only created this project to satisfy my own TTS needs, so I haven’t had to explore beyond Polly :)
However, I understand how having a Google Cloud option would be useful to others. If people are interested in this option, I could certainly look into it. And the project is open source, so anyone can submit a patch to add Google support.
I’ll take a look at their API in the next day or so to get an idea of the scope. Thanks for bringing it to my attention.
Eric
Eric |
I created an issue if anyone wants to give it a thumbs-up (or thumbs-down) reaction: https://github.com/eheikes/aws-tts/issues/32
A.V. |
Hi,
Thank you for developing this. Once I get it working, it will really hit the spot.
I have essentially no homebrew experience but really want to have my schoiol materials transcribed using Polly. I’ll appreciate any help. Thanks.
I installed homebrew. Node.js. ffmpeg.
macOS High Sierra 10.13.3
Running aws-tts seems to successfully read text, split text, and convert to audio (99/99). However, it fails to combine audio.
I think this is the pertinent error:
[mp3 @ 0x7f8796008600] Format mp3 detected only with low score of 1, misdetection possible!
[mp3 @ 0x7f8796008600] Failed to read frame size: Could not seek to 1030.
[concat @ 0x7f8796000000] Impossible to open ‘/var/folders/xl/mwfv7m896z1g2fnr6c3mrgy00000gn/T/bc1cd827-1d0c-419a-876d-c632eb7ca72a.mp3’
/var/folders/xl/mwfv7m896z1g2fnr6c3mrgy00000gn/T/0b32618a-458b-47ea-92d2-7d18b0c67c9c.txt: Invalid argument
I’ll appreciate any guidance. Thanks,
AV
Eric |
Hi AV!
That’s an interesting error… It’s coming from ffmpeg. Can you provide me with any of the following info?
1) Run `node -v; ffmpeg -version` (without the quotes) in the terminal and paste the output here.
2) Run `file /var/folders/xl/mwfv7m896z1g2fnr6c3mrgy00000gn/T/bc1cd827-1d0c-419a-876d-c632eb7ca72a.mp3` and `cat /var/folders/xl/mwfv7m896z1g2fnr6c3mrgy00000gn/T/0b32618a-458b-47ea-92d2-7d18b0c67c9c.txt` in the terminal and paste the output here.
3) What is the exact aws-tts command you are running?
4) If possible, upload the text file to pastebin.com or somewhere and link to it here.
Thanks,
Eric
AV |
Thanks for the help. Here you go.
1)
v9.4.0
ffmpeg version N-89776-gb94cd55155-tessus Copyright (c) 2000-2018 the FFmpeg developers
built with Apple LLVM version 9.0.0 (clang-900.0.39.2)
configuration: –cc=/usr/bin/clang –prefix=/opt/ffmpeg –extra-version=tessus –enable-avisynth –enable-fontconfig –enable-gpl –enable-libass –enable-libbluray –enable-libfreetype –enable-libgsm –enable-libmodplug –enable-libmp3lame –enable-libopencore-amrnb –enable-libopencore-amrwb –enable-libopus –enable-libsnappy –enable-libsoxr –enable-libspeex –enable-libtheora –enable-libvidstab –enable-libvo-amrwbenc –enable-libvorbis –enable-libvpx –enable-libwavpack –enable-libx264 –enable-libx265 –enable-libxavs –enable-libxvid –enable-libzmq –enable-libzvbi –enable-version3 –pkg-config-flags=–static –disable-ffplay
libavutil 56. 7.100 / 56. 7.100
libavcodec 58. 9.100 / 58. 9.100
libavformat 58. 3.100 / 58. 3.100
libavdevice 58. 0.100 / 58. 0.100
libavfilter 7. 11.101 / 7. 11.101
libswscale 5. 0.101 / 5. 0.101
libswresample 3. 0.101 / 3. 0.101
libpostproc 55. 0.100 / 55. 0.100
2)
/var/folders/xl/mwfv7m896z1g2fnr6c3mrgy00000gn/T/bc1cd827-1d0c-419a-876d-c632eb7ca72a.mp3: cannot open `/var/folders/xl/mwfv7m896z1g2fnr6c3mrgy00000gn/T/bc1cd827-1d0c-419a-876d-c632eb7ca72a.mp3′ (No such file or directory)
cat: /var/folders/xl/mwfv7m896z1g2fnr6c3mrgy00000gn/T/0b32618a-458b-47ea-92d2-7d18b0c67c9c.txt: No such file or directory
3) I used the command ‘aws-tts AuthorDatetxt2Polly.txt AuthorDate.mp3 —access-key [KEY] —format mp3’
4) https://pastebin.com/SP8d3PXk
Eric |
(This conversation has continued at https://github.com/eheikes/aws-tts/issues/22)
Aaron |
Hi, this is an amazing tool. I’ve been trying to find a reliable way to convert text into quality TTS for a while, mainly so I can review my own writing on the drive to and from work.
I was able to install the components and connect to my AWS without fail, and can generate the audio from a standard text file. However, I’m having a hard time getting it to parse the SSM Language. It keeps returning an error that it’s an Invalid SSML Request.
I’ve tried many variations of the mark-up inside the file, and the file itself is a .xm1 file (and a .txt file, but neither worked).
Do you have an example of a valid SSML file with text in it that I could use as a template? I’d love to be able to utilize tags. Thank you again – this is great, either way.
Eric |
Hi Aaron, thanks for the kind words.
I’ve only tried simple SSML files, but they’ve seemed to work. The file extension shouldn’t matter, but you’ll have to specify “ssml” as the type:
aws-tts test.ssml test.mp3 –type ssml
Here is the SSML file that I used: https://gist.github.com/eheikes/7d47a9f70b2dd07de0ee408fadf4626b
If you can share an example SSML that doesn’t work for you, I can take a closer look.
Eric
Bruce |
Hi Eric, thanks a lot for your magic codes. I don’t have much experience in coding. Could you please take a look at the error codes I had below? Thanks.
aws-tts test.txt test.mp3
✔ Reading text
✔ Splitting text
✖ Convert to audio (4/282)
HTTPError: Response code 403 (Forbidden)
at EventEmitter.ee.on.res (/usr/local/lib/node_modules/aws-tts/node_modules/got/index.js:182:24)
at emitOne (events.js:96:13)
at EventEmitter.emit (events.js:188:7)
at Immediate.setImmediate (/usr/local/lib/node_modules/aws-tts/node_modules/got/index.js:61:8)
at runCallback (timers.js:672:20)
at tryOnImmediate (timers.js:645:5)
at processImmediate [as _immediateCallback] (timers.js:617:5)
Eric |
Hi Bruce,
That 403 error is coming from AWS, and I’m guessing your credentials are not being accepted. Make sure that you have set up your AWS keys as described in the documentation: https://github.com/eheikes/aws-tts#requirements–installation
You can use the AWS CLI tool (https://aws.amazon.com/cli/) to check your configuration… running something like `aws sts get-caller-identity` should return the user info.
Eric
Gareth Bowker |
Hi Eric,
Incidentally, I got the same error as above earlier today, when I tried using a lexicon that didn’t exist (well, I had the lexicon in a European region, and was using the default US region). Once I added a –region option to the correct place, it all worked again.
Gareth
Hugo B |
Hi have you figured out a way to overcome the 1500 character limit? can I make a loop on php? suggestions or code examples appreciated.
Eric |
Hi Hugo,
The 1500 character limit is built-in to the AWS Polly API; there’s no way around it. (Other than using a tool like the one mentioned in this post!)
As far as PHP goes, I haven’t used it with Polly. If you haven’t checked out the official documentation yet, go to http://docs.aws.amazon.com/AmazonS3/latest/dev/UsingTheMPphpAPI.html to get started, and check out the example project at https://github.com/awslabs/aws-php-sample
Hugo B |
Hi again… As a way to find a solution to the character limit. I was able to make use of another TTS interface provided by IBM, with this second option. I was able to make use of additional new voices and free myself from the limit actually imposed by AWS. I will be holding a meeting online with them next week, so I will bring up that subject to either create that feature or have an API option or workaround to make it work. I hope this post is useful to you and other users who may have a similar scenario.
Mac |
Hi, great tool you created. I wonder if we can compress mp3 file size more.
1 min of mp3 file cost 442 KB, that was awfully a lot.
Eric |
Hi Mac,
AWS does allow a smaller sample rate to be specified, but it’s not supported in the aws-tts tool yet. I’ve created an issue to add support soon: https://github.com/eheikes/aws-tts/issues/12
Eric
Eric |
As of v1.2.0 you can specify the sample rate using the –sample-rate option.
https://github.com/eheikes/aws-tts/releases/tag/v1.2.0
Danilo |
Hi,
I’m trying to use your nice software but when I try to convert even a simple text file I always get this error:
>aws-tts prova.txt prova.mp3
V Reading text
V Splitting text
V Convert to audio (1/1)
× Combine audio
Error: ffmpeg returned an error (1)
at ChildProcess.ffmpeg.on.code (C:\Users\Danilo\AppData\Roaming\npm\node_mod
ules\aws-tts\lib.js:160:25)
at emitTwo (events.js:106:13)
at ChildProcess.emit (events.js:194:7)
at maybeClose (internal/child_process.js:899:16)
at Socket. (internal/child_process.js:342:11)
at emitOne (events.js:96:13)
at Socket.emit (events.js:191:7)
at Pipe._handle.close [as _onclose] (net.js:511:12)
Could you help me, please?
Thanks
Eric |
Hi Danilo,
Thanks for reporting this. I’ll see if I can reproduce it myself. I think I know what the problem may be.
In the meantime, can you verify that ffmpeg is working on your computer? Running `ffmpeg.exe -version` on the command line should print the ffmpeg details.
Thanks,
Eric
Danilo |
Hi Eric,
I think it’s working. This is the version:
ffmpeg version 3.2.4 Copyright (c) 2000-2017 the FFmpeg developers
built with gcc 6.3.0 (GCC)
configuration: –enable-gpl –enable-version3 –enable-d3d11va –enable-dxva2 —
enable-libmfx –enable-nvenc –enable-avisynth –enable-bzlib –enable-fontconfi
g –enable-frei0r –enable-gnutls –enable-iconv –enable-libass –enable-libblu
ray –enable-libbs2b –enable-libcaca –enable-libfreetype –enable-libgme –ena
ble-libgsm –enable-libilbc –enable-libmodplug –enable-libmp3lame –enable-lib
opencore-amrnb –enable-libopencore-amrwb –enable-libopenh264 –enable-libopenj
peg –enable-libopus –enable-librtmp –enable-libsnappy –enable-libsoxr –enab
le-libspeex –enable-libtheora –enable-libtwolame –enable-libvidstab –enable-
libvo-amrwbenc –enable-libvorbis –enable-libvpx –enable-libwavpack –enable-l
ibwebp –enable-libx264 –enable-libx265 –enable-libxavs –enable-libxvid –ena
ble-libzimg –enable-lzma –enable-zlib
libavutil 55. 34.101 / 55. 34.101
libavcodec 57. 64.101 / 57. 64.101
libavformat 57. 56.101 / 57. 56.101
libavdevice 57. 1.100 / 57. 1.100
libavfilter 6. 65.100 / 6. 65.100
libswscale 4. 2.100 / 4. 2.100
libswresample 2. 3.100 / 2. 3.100
libpostproc 54. 1.100 / 54. 1.100
Thank you
Eric |
This issue is being tracked here: https://github.com/eheikes/aws-tts/issues/9
I should be able to fix it this week.
Eric |
Danilo,
This should be fixed now. Can you see if it works with the latest version?
`npm install aws-tts@1.0.4 -g`
Danilo |
Hi Eric,
now it works! Great job, thank you. ;)
See you
Danilo
Alan Akin |
I have the same problem as Danilo.